2026-04-22
Detecting What You’ve Never Seen: OOD Robustness in Document Portrait Forgery Detection
SpoofSense Research tests DocLive-Zero against unseen document templates, capture conditions, and AI-generated portrait swaps.
Measuring Out-of-Distribution Robustness in Document Portrait Forgery Detection
SpoofSense Research · April 2026
Abstract
We investigate the out-of-distribution (OOD) generalization capability of an experimental document portrait forgery detector trained under data constraints. Our experimental model, DocLive-Zero, is trained exclusively on a small corpus of naive bounding-box-based portrait substitutions, geometrically placed face crops with no harmonization, and no generative-AI-produced samples of any kind. We evaluate under two distribution shifts: (1) unseen international document templates with unseen capture conditions, and (2) compound OOD — unseen templates, unseen conditions, and unseen AI-generated portrait swaps from three generator families spanning GAN and diffusion architectures. Against a fully fine-tuned resnet50 baseline trained on identical data, DocLive-Zero achieves 94.7% AUC and 86.9% AUC under compound OOD. We present forensic & interpretability analysis to characterize the nature and limits of the observed generalization.
1. Introduction
Document forgery detection pipelines face a structural scalability problem. Identity documents vary across thousands of templates issued by hundreds of jurisdictions, with periodic format revisions, evolving security features, and increasingly sophisticated forgery techniques. The dominant paradigm — supervised classification trained on labeled examples of each document type and each attack method — achieves strong in-distribution performance but degrades under distribution shift. Adding a new document template or defending against a new forgery technique requires collecting and labeling new data, retraining, and revalidating. At scale, this creates compounding operational cost.
The emergence of generative AI intensifies this problem. Diffusion-based image editing models (Nano Banana Pro, Flux2 Pro) and GAN-based pipelines (InsightFace) produce portrait substitutions with sophisticated color harmonization, lighting adaptation, and boundary inpainting that differ fundamentally from traditional cut-and-paste forgeries. A model trained to detect crude manipulations cannot be assumed to generalize to these novel attack distributions without explicit evaluation.
We pose the following question: can a model trained on minimal, rudimentary manipulation data learn a sufficiently general representation of document-portrait inconsistency that it transfers to unseen document formats, unseen capture conditions, and unseen AI-generated attack methods — simultaneously?
To test this, we impose a deliberate constraint. We train DocLive-Zero on a small dataset using a trivial manipulation technique (bounding-box portrait substitution), then evaluate on two progressively harder OOD conditions:
- Level 1: Unseen international document templates + unseen capture conditions. Attack methods structurally similar to training.
- Level 2: Unseen templates + unseen conditions + unseen AI-generated attacks (GAN and diffusion). Compound distribution shift across all three axes simultaneously.
We compare against a standard supervised baseline (resnet50, fully fine-tuned) trained on identical data, and present forensic, interpretability, and failure analyses to characterize the nature of the observed generalization.
2. Experimental Setup
2.1 Training Constraints
DocLive-Zero is trained under deliberately restrictive conditions:
Training data. A small corpus of identity document images with programmatically generated portrait forgeries. Each forged sample is constructed by detecting the portrait bounding box on a source document, cropping a donor face, and pasting it at the detected coordinates. No color transfer, no inpainting. The resulting manipulations exhibit hard boundary edges, color discontinuities, and resolution mismatches — artifacts that are trivially detectable by visual inspection.
No generative AI in training. The training set contains zero samples produced by diffusion models, GANs, VAEs, or any other generative framework. No face-swap networks (InsightFace, SimSwap, FaceFusion, etc.) were used. All manipulations are purely geometric.
This design is intentional. We seek to determine whether a model can extract a general concept of document-portrait inconsistency from clear, unambiguous training signals — and whether that concept transfers to manipulations that are qualitatively different from anything observed during training.
2.2 Baseline
We train a ResNet-50 on identical training data — same images, same labels, same train/validation split. This represents the standard paradigm: a well-established CNN architecture, pretrained on a large natural image corpus, adapted to the target task via end-to-end supervised fine-tuning.
The comparison is not a controlled ablation of a single variable — the models differ in architecture, capacity, and pretraining distribution. Rather, it compares two practical paradigms a practitioner might select when building a document forgery detector: (a) end-to-end fine-tuning of a standard CNN, vs. (b) the approach underlying DocLive-Zero. Same data, different learning paradigms, same evaluation protocol.
2.3 Evaluation Protocol
Level 1 — Template and condition generalization. An external dataset of document portrait attacks collected independently by a research group for publication at a peer-reviewed biometrics venue. The dataset includes international ID formats, capture devices, and imaging conditions absent from training. Manipulation methods (portrait substitution) are structurally similar to training data, isolating template and condition shift as the primary OOD axes.
Level 2 — Compound OOD. We sample a smaller subset from Level 1 document images (unseen templates, unseen conditions) and apply AI-generated portrait swaps using three generator families:
| Generator | Architecture | Method |
|---|---|---|
| Nano Banana Pro | Diffusion | Portrait inpainting via denoising |
| InsightFace / Codeplug | GAN | Feature-level face swap |
| Flux2 Pro | Diffusion | High-fidelity portrait inpainting |
None of these generators, their outputs, or any generative-AI-based manipulation appears in DocLive-Zero's training data. Level 2 represents simultaneous distribution shift across document template, capture condition, and attack method — the hardest evaluation condition we could construct.
Metrics. We report AUC (area under the ROC curve), overall accuracy, ACER (average classification error rate), BPCER (bona fide presentation classification error rate — false rejection of genuine documents), and APCER (attack presentation classification error rate — false acceptance of attacks). BPCER is critical for production viability: a model that catches attacks but rejects a large fraction of legitimate documents is operationally unusable.
3. Why This Is Hard: Forensic Analysis of the Distribution Gap
Before presenting detection results, we examine the forensic properties of the test-time attacks to establish that the distribution gap between training and evaluation is genuine and severe.
3.1 Error Level Analysis (ELA)
Error Level Analysis reveals compression inconsistencies in manipulated images by re-saving at a fixed quality level and computing the pixel-wise difference. Different manipulation methods produce qualitatively different ELA signatures:
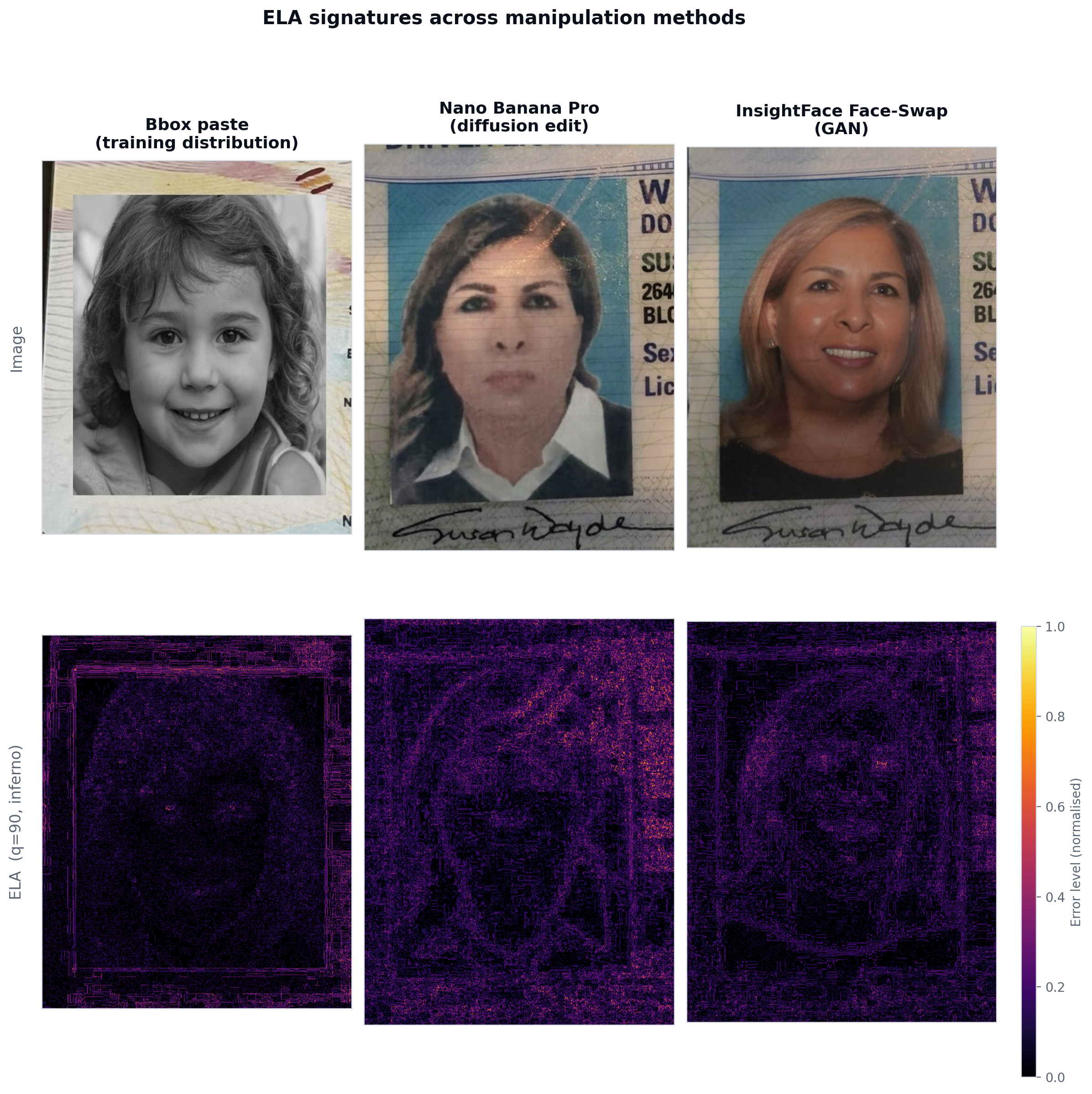
[Figure 1] ELA comparison across manipulation methods. Columns (left → right): bounding-box paste from the training distribution, Nano Banana Pro diffusion edit on a driver license, and InsightFace GAN-based face-swap on the same card. Top row: tampered image. Bottom row: ELA heatmap. The bbox paste produces a sharp, near-rectangular high-energy boundary at the portrait edge — exactly the artifact the training set teaches. The diffusion edit spreads its energy diffusely across the entire portrait region with no clean boundary. The GAN face-swap concentrates its signal in a soft oval over the face itself, with the surrounding card untouched. The artifact profiles are qualitatively different — a detector trained on the first signature cannot be assumed to recognise the other two.
3.2 Frequency Domain Analysis (2D DCT)
We compute the 2D discrete cosine transform of the portrait region for each manipulation method. The frequency-domain signatures differ substantially:

[Figure 2] 2D DCT spectrum of the portrait region. Columns (left → right): bounding-box paste from the training distribution, Nano Banana Pro diffusion edit, InsightFace GAN face-swap. Top row: portrait crop. Bottom row: log-magnitude 2D DCT-II spectrum, DC at top-left, normalised per image and rendered with
magma. The bbox paste shows sharp high-frequency energy along the axis lines — the spectral fingerprint of the rectangular substitution boundary. The diffusion edit attenuates high-frequency detail across the whole spectrum, consistent with the denoising process smoothing out the fine texture. The GAN swap concentrates periodic mid-frequency energy in the off-axis bands — the characteristic "stripe" pattern produced by upsampling layers. Each generation paradigm leaves a distinct spectral fingerprint — the model cannot rely on any single frequency pattern for detection.
The forensic analysis confirms that the OOD gap in this experiment is not incremental. It is a categorical shift in artifact type, spatial distribution, and frequency signature. A model that generalizes across this gap has learned something beyond surface-level artifact matching.
4. Level 1 — Template and Condition Generalization
At Level 1, we evaluate on the external academic dataset with unseen document formats and capture conditions. Attack methods (portrait substitution) are structurally similar to training data.
Results
| Model | AUC | Accuracy | ACER | BPCER | APCER |
|---|---|---|---|---|---|
| DocLive-Zero | 94.7% | 87.0% | 13.0% | 15.6% | 10.4% |
| ResNet-50 (baseline) | 69.3% | 65.2% | 34.8% | 34.7% | 34.9% |
Key finding. On identical training data, DocLive-Zero achieves 94.7% AUC on unseen international document templates — a 25.4 percentage point advantage over the ResNet-50 baseline. The gap is not marginal; it represents a qualitatively different level of template generalization.
The ResNet-50 baseline's near-symmetric error profile (BPCER ≈ APCER ≈ 35%) suggests it has not learned a meaningful decision boundary for this task under distribution shift — its performance approaches informed random classification. DocLive-Zero's asymmetric error profile (BPCER 15.6%, APCER 10.4%) indicates a model that has learned to preferentially pass genuine documents while catching the majority of attacks.
Operational implication. Document templates are not static. Governments issue redesigned identity documents, update security features, and introduce new digital ID programs. A model that requires retraining for each template change creates ongoing operational cost proportional to the number of supported jurisdictions. A model that maintains 94.7% AUC on templates absent from training data can be deployed in new geographies where training data is scarce, expensive to acquire, or nonexistent.
5. Level 2 — Compound OOD: Everything Unseen
Level 2 applies AI-generated portrait swaps (Nano Banana Pro, InsightFace/Codeplug, Flux2 Pro) to the Level 1 documents. This produces simultaneous distribution shift across template, capture condition, and attack method. No dimension of the test distribution overlaps with training.
Recall that DocLive-Zero's training data consists exclusively of bounding-box portrait pastes. It has never observed a diffusion model's output, a GAN's output, or any AI-generated manipulation. It has never seen these document formats. It has never encountered these capture conditions.
Results
| Model | AUC | Accuracy | ACER | BPCER | APCER |
|---|---|---|---|---|---|
| DocLive-Zero | 86.9% | 78.3% | 21.7% | 16.9% | 26.4% |
| ResNet-50 (baseline) | 74.7% | 68.7% | 31.3% | 38.0% | 24.6% |
Key finding. Under compound OOD — the hardest condition we could construct — DocLive-Zero achieves 86.9% AUC with a 12.2 percentage point advantage over the baseline. Critically, DocLive-Zero maintains BPCER of 16.9% (approximately 1 in 6 genuine documents falsely rejected), while ResNet-50's BPCER rises to 38.0% (more than 1 in 3). In a production deployment, this difference determines whether the system is usable.
An important nuance: on raw attack detection (APCER), the models are closer than the AUC gap suggests — 26.4% vs. 24.6%. ResNet-50 achieves comparable attack catch rates, but only by adopting an aggressive decision boundary that rejects a disproportionate share of genuine documents. DocLive-Zero achieves its attack detection while maintaining a production-viable specificity. This is the difference between a model that can be deployed and a model that cannot.
Degradation Profile
The performance trajectory from Level 1 to Level 2 reveals how each model responds to compounding distribution shift:
| Model | Level 1 AUC | Level 2 AUC | Δ AUC |
|---|---|---|---|
| DocLive-Zero | 94.7% | 86.9% | −7.8pp |
| ResNet-50 | 69.3% | 74.7% | +5.4pp |
DocLive-Zero degrades gracefully (−7.8pp). ResNet-50 nominally improves (+5.4pp), but this is misleading — its Level 1 performance was already near chance (69.3%), and its Level 2 "improvement" comes at the cost of a 38% false rejection rate. At any fixed BPCER operating point, DocLive-Zero dominates across both conditions.
6. Interpretability Analysis
Feature Space Structure (t-SNE)
We extract penultimate-layer representations from both models for all Level 2 test samples and project to 2D using t-SNE:
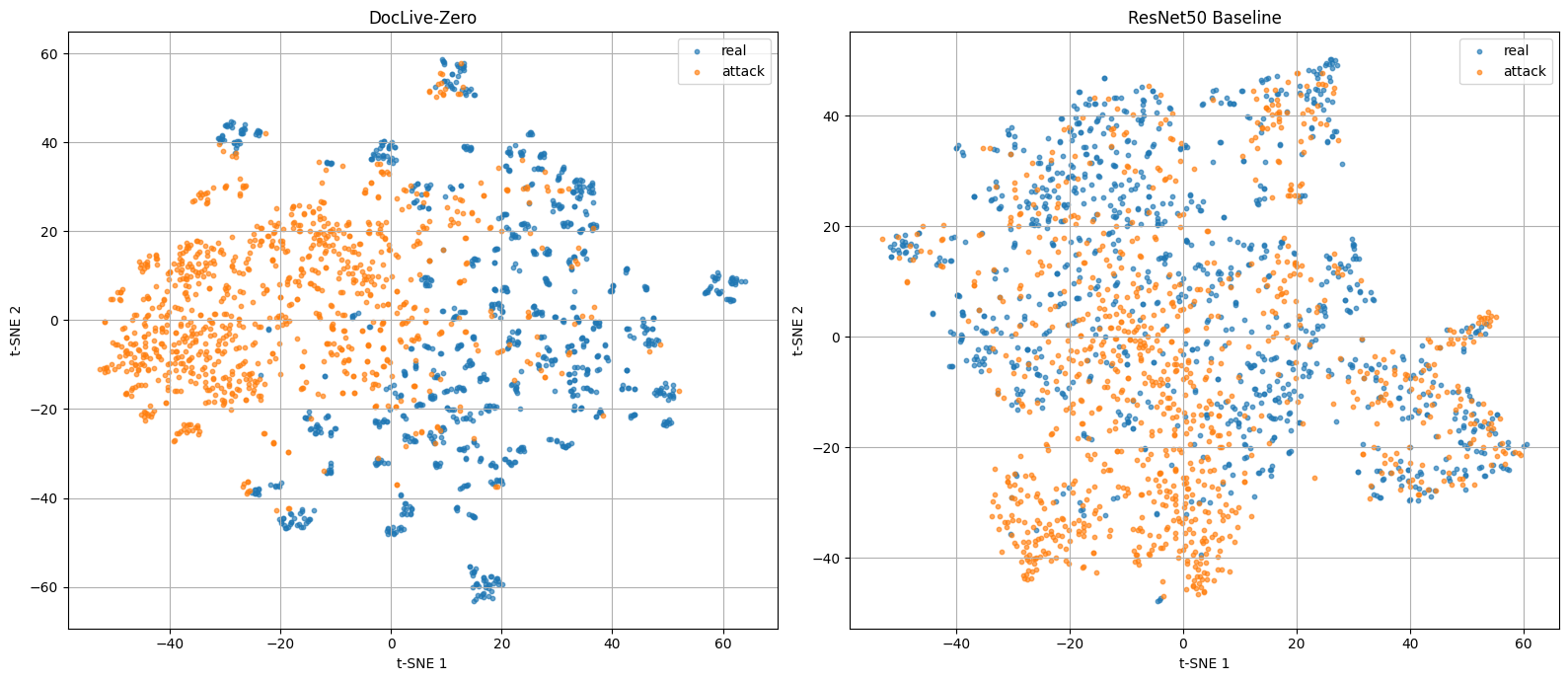
[Figure 7] t-SNE embeddings colored by class (genuine vs. attack). Left: DocLive-Zero. Right: ResNet-50. DocLive-Zero's feature space exhibits visible clustering — tampered documents occupy predominantly distinct regions from genuine documents, with partial overlap in a central transition zone. ResNet-50's feature space shows no discernible class structure; genuine and attacked samples are uniformly intermixed.
The contrast between the two feature spaces is striking. ResNet-50 — trained on identical data — has not learned to separate genuine from manipulated documents in its representation space. DocLive-Zero has, and the separation generalizes across generators the model has never encountered. The difference is not in the training data. It is in what each model extracts from that data.
7. Failure Analysis
We examine DocLive-Zero's false negatives on Level 2 — manipulated documents that were incorrectly classified as genuine — by the generator that produced them.
7.1 APCER by generator
Not all generators fool the model equally. We compute APCER separately for each generator family, excluding API errors from the denominator:
| Generator | APCER |
|---|---|
| Flux2 Pro (diffusion) | 50.0% |
| Nano Banana Pro (diffusion) | 23.8% |
| InsightFace / Codeplug (GAN) | 7.5% |
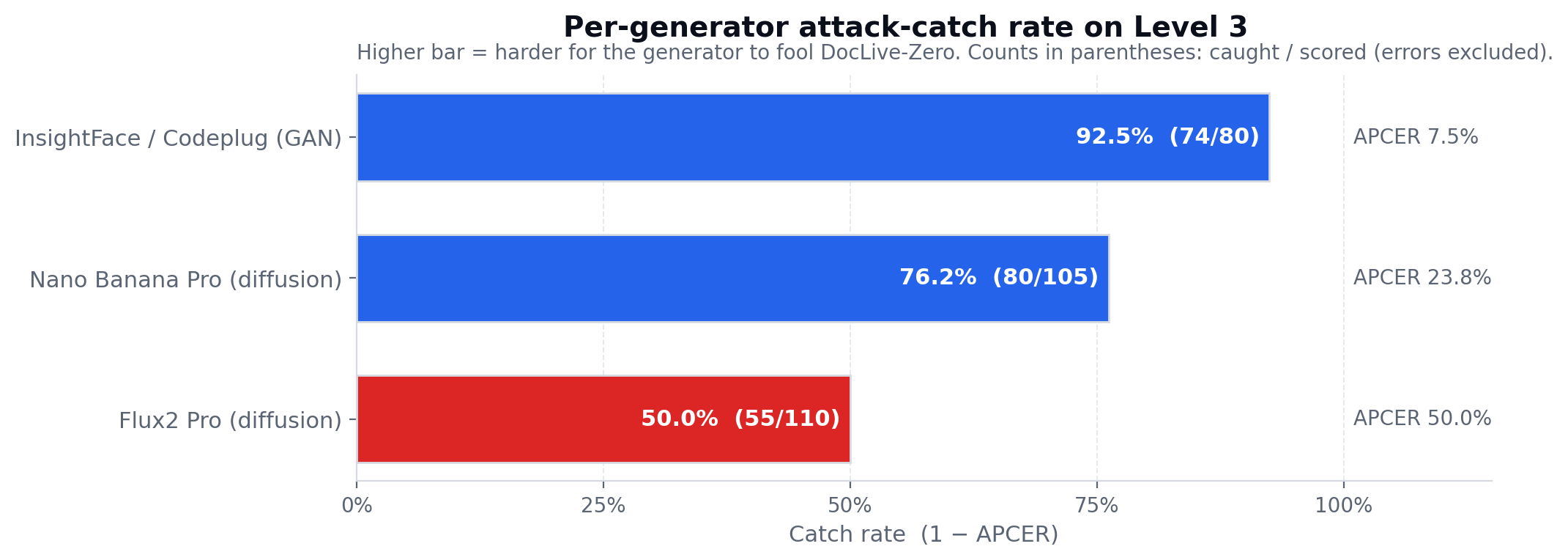
[Figure 8a] Per-generator catch rate on Level 2. The GAN face-swap is caught on 92.5% of samples; Flux2 Pro — the strongest diffusion generator we tested — succeeds roughly half the time.
The GAN swap leaves the most distinctive high-frequency "upsampling stripe" signature and the most localised ELA response, yet it is also the generator that preserves the surrounding card context most faithfully — the document background, card texture, and pose are untouched, while only the face pixels change. The diffusion generators — Nano Banana Pro and especially Flux2 Pro — re-synthesise a wider neighbourhood and harmonise colour, lighting, and texture across the portrait-document boundary. That harmonisation is precisely what the model is looking for the absence of.
The gap between the two diffusion generators (23.8% vs. 50.0% APCER) is itself informative. Both are diffusion-based portrait inpainters, but Flux2 Pro produces a markedly smoother portrait-to-document transition at our chosen parameters, consistent with a more aggressive denoising schedule over a larger inpainting region.
7.2 Qualitative failures

[Figure 8b] Hardest cases: Missed Tamper Attacks ranked by DocLive-Zero's portrait-tamper score (most "live" first). Top row: full tampered ID. Bottom row: portrait crops. All top-ranked misses are Flux2 Pro diffusion outputs — consistent with its 50% APCER.
Across the top-ranked misses the failure signature is consistent: the generator has matched skin tone, lighting direction, and colour temperature to the surrounding card; the inpainted region carries the same apparent resolution and micro-texture as the document; and the portrait-document boundary has been smoothed to the point where the inconsistency signal falls below the model's detection threshold.
8. Limitations
Attack type coverage. We evaluate only portrait swap / face replacement attacks. Other document manipulation types — text field editing, barcode forgery, full synthetic document generation, copy-move forgery — remain untested. Generalization to portrait forgery does not imply generalization to all document fraud categories.
Generator coverage. Three generator families were evaluated. The space of possible generation methods is large and evolving. Performance on untested generators — particularly future architectures — is unknown.
Sample size. The Level 2 evaluation set contains approximately 300 manipulated samples across three generators. While sufficient for directional conclusions, larger-scale evaluation with additional generators and document types would strengthen statistical confidence.
Baseline scope. We compare against a single baseline architecture (ResNet-50). A more comprehensive study would include additional architectures (ViT, EfficientNet, ConvNeXt) and training strategies to better isolate the source of the generalization advantage.
Paradigm comparison. DocLive-Zero and the ResNet-50 baseline differ in architecture, capacity, and pretraining. The comparison illustrates a practical paradigm choice, not a controlled ablation. Isolating the contribution of individual factors (backbone architecture, pretraining data scale, fine-tuning strategy) requires further experimentation.
Production conditions. All evaluation was conducted on curated datasets. Production deployment introduces additional challenges: device diversity, lossy compression pipelines, adversarial feedback loops, and distributional non-stationarity in fraud patterns.
9. Discussion
We trained an experimental model on a small dataset using the simplest possible manipulation technique — geometrically pasting a cropped face onto a document at bounding-box coordinates. No blending. No generative AI. No diversity of attack methods. We then evaluated on AI-generated portrait swaps from three generator families, on international document formats the model has never seen, under capture conditions absent from training.
The results show that DocLive-Zero achieves 94.7% AUC on unseen templates with known attack types (Level 1), and 86.9% AUC under compound OOD where templates, conditions, and attack methods are all unseen simultaneously (Level 2). A ResNet-50 baseline trained on identical data achieves 69.3% and 74.7% respectively — and at the cost of rejecting 38% of legitimate documents under compound OOD, rendering it non-deployable.
The interpretability analysis suggests a mechanism: DocLive-Zero has learned to attend to the portrait-document boundary region and detect inconsistencies at that interface. This pattern, learned from crude paste artifacts where the inconsistency signal is strong and obvious, transfers to AI-generated swaps where the signal is subtle but structurally present. The model did not learn "what bounding-box pastes look like." It learned "what document-portrait inconsistency looks like" — and that concept generalizes.
Two models. Same data. Dramatically different outcomes. The difference is not in the labels. It is in the learning.
Whether this principle extends beyond portrait forgery — to document tamper detection, security feature verification, or full synthetic document detection — is an open question we are actively investigating.
© 2026 SpoofSense · Bangalore, India · spoofsense.ai